Meta x Lamini: Tune Llama 3 to query enterprise data safely and accurately
Meta x Lamini
Lamini and Meta are teaming up to make it easy to build powerful LLM applications with Llama 3.
This tutorial demonstrates how to tune Llama 3 with Lamini Memory Tuning for a SQL LLM to remove hallucinations, lift accuracy to 95%, and continually improve it. By improving the quality of SQL queries generated, you'll be able to improve upon Llama 3's baseline performance. Try it yourself:
Meta Llama 3 Lamini recipe repo: https://github.com/meta-llama/llama-cookbook/tree/main/3p-integrations/lamini/text2sql_memory_tuning
Why is this useful?
- Faster answers for business users, reducing response time by up to 50%.
- Less data team time spent answering simple questions, decreasing their workload by approximately 30%.
- More reliable than business users writing their own queries without the data knowledge that the model gets from tuning, achieving a 95% accuracy rate compared to 75% for untrained users.
For this tutorial, you’ll go through several iterations of creating data generation LLMs, model evaluation LLMs, and Lamini Memory Tuning of the model:
- Generate SQL queries with Llama 3
- Develop an Evaluation (Eval) that is scalable and robust
- Auto-generate data to Memory Tune Llama 3
- Iterate and Memory Tune Again
Step 1: Create a SQL LLM with Llama 3 and Diagnose Hallucinations

You can first establish baseline performance with Llama 3 to understand what the behavior of calling an off-the-shelf API can provide. Here’s an example query with Llama 3 using prompt tuning and a system prompt.
You'll use the nba_roster database, which contains information about NBA players, teams, and games. This database will serve as the foundation for your tuning process.
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
def make_llama_3_prompt(user, system=""):
system_prompt = ""
if system != "":
system_prompt = (
f"<|start_header_id|>system<|end_header_id|>\n\n{system}<|eot_id|>"
)
return f"<|begin_of_text|>{system_prompt}<|start_header_id|>user<|end_header_id|>
\n\n{user}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
question = """Who is the highest paid NBA player?"""
system = f"""\
You are an NBA analyst with 15 years of experience writing complex SQL queries.
Consider the nba_roster table with the following schema:
0|Team|TEXT eg. "Toronto Raptors"
1|NAME|TEXT eg. "Otto Porter Jr."
2|Jersey|TEXT eg. "0" and when null has a value "NA"
3|POS|TEXT eg. "PF"
4|AGE|INT eg. "22" in years
5|HT|TEXT eg. `6' 7"` or `6' 10"`
6|WT|TEXT eg. "232 lbs"
7|COLLEGE|TEXT eg. "Michigan" and when null has a value "--"
8|SALARY|TEXT eg. "$9,945,830" and when null has a value "--"
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)
# Ask the model to generate a sql query to answer the question
print(llm.generate(prompt, max_new_tokens=200))
Llama 3 will respond with the following:
To answer this question, we can use the following SQLite query:
```sql
SELECT NAME, SALARY
FROM nba_roster
WHERE SALARY!= '--'
ORDER BY CAST(SALARY AS REAL) DESC
LIMIT 1;
```
This query first filters out the rows where the salary is '--'
(i.e., the players who do not have a salary listed). Then,
it orders the remaining rows by the salary in descending order
(highest to lowest). Finally, it returns the top row, which
corresponds to the highest paid NBA player.
This is interesting but there are few things wrong with it:
- The response must be parsed to extract the sql query.
- The query is incorrect—it returns
Saddiq Beymaking$4,556,983instead ofStephen Currymaking$51,915,615!
Step 2: Create an Evaluation Dataset
An Evaluation Dataset is a representative dataset to measure your model’s performance. An Evaluation Dataset can start with as few as 20-100 data points. The goal is to get started quickly on improving your model, so don’t get bogged down—it’s fine to start small.
Here are a few example data points from a reference dataset. Note the question, answer, sql structure—we need all three to assess the model’s accuracy.
{'answer': '24',
'question': "What's the average age of the Trail Blazers?",
'sql': "select avg(age) from nba_roster where team='Portland Trail "
"Blazers';"},
{'answer': '25',
'question': "What's the median age of the NBA?",
'sql': 'select CAST(AGE as INTEGER) as percentile from nba_roster order by '
'percentile limit 1 offset (select count(*) from nba_roster)/2;'},
{'answer': '26',
'question': "What's the median age of the Miami Heat?",
'sql': 'select CAST(AGE as INTEGER) as percentile from nba_roster where '
"team='Miami Heat' order by percentile limit 1 offset (select "
"count(*) from nba_roster where team='Miami Heat')/2;"},
{'answer': 'Golden State Warriors, Milwaukee Bucks, Miami Heat, LA Clippers, '
'Phoenix Suns',
'question': 'What are the 5 teams with the oldest average age in the NBA',
'sql': 'SELECT team, AVG(AGE) AS average_age FROM nba_roster GROUP BY team '
'ORDER BY average_age DESC LIMIT 5;'},
{'answer': '$10948045',
'question': 'What is the average salary of Power Forward players in the NBA',
'sql': "select avg(CAST(REPLACE(REPLACE(SALARY, '$', ''), ',','') AS "
"INTEGER)) as average_salary from nba_roster where POS = 'PF';"}
You can do it! Writing an initial evaluation dataset can feel tedious, but a minor investment in time can lead to drastic improvement in quality. Some rough time estimates: it took ~20 minutes to write 20 queries, leading to a jump in perf from 25% to 75%. A more intense ~1 hour long data generation and cleaning workflow improved perf from 75% to 95%.
Step 3: Evaluate the SQL LLM with an Eval LLM
To get evaluation results faster, we’ll use Lamini’s Inference Pipeline SDK. First, define a QueryStage and ScoreStage by extending the GenerationNode class. We can take the following steps during the evaluation:
Query Stage
- Model generates SQL query
- Run SQL query against SQLite database
- Run Evaluation Dataset SQL query against SQLite database
class QueryStage(GenerationNode):
def __init__(self, model_name):
super().__init__(
model_name=model_name,
max_tokens=400,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"sqlite_query": "str"},
*args,
**kwargs,
)
return results
def postprocess(self, obj: PromptObject):
# Run both the generated and reference (Gold Dataset) SQL queries
# Assessing whether the SQL queries succeeded in hitting the database (not correctness yet!)
query_succeeded = False
try:
obj.data["generated_query"] = obj.response["sqlite_query"]
df = pd.read_sql(obj.response["sqlite_query"], con=engine)
obj.data['df'] = df
query_succeeded = True
except Exception as e:
logger.error(
f"Failed to run SQL query: {obj.response['sqlite_query']}"
)
df = pd.read_sql(obj.data["sql"], con=engine)
obj.data['reference_df'] = df
obj.data["query_succeeded"] = query_succeeded
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_prompt(obj.data))
obj.prompt = new_prompt
def make_prompt(self, data: dict):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += "Consider the nba_roster table with the following schema:\n"
system += get_schema() + "\n"
system += (
"Write a sqlite SQL query that would help you answer the following question:\n"
)
user = data["question"]
return {
"user": user,
"system": system,
}
Score Stage
- Compare model query result and Evaluation Dataset query result
class ScoreStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_tokens=400,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={"explanation": "str", "similar": "bool"},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
obj.prompt = make_llama_3_prompt(**self.make_prompt(obj))
def postprocess(self, obj: PromptObject):
obj.data['is_matching'] = self.is_matching(obj.data, obj.response)
obj.data['explanation'] = obj.response["explanation"]
obj.data['similar'] = obj.response["similar"]
def is_matching(self, data, response):
return (str(data.get('df',"None")).lower() == str(data['reference_df']).lower()
or response['similar'])
def make_prompt(self, obj: PromptObject):
# Your evaluation model compares SQL output from the
# generated and reference SQL queries, using another
# LLM in the pipeline
system_prompt = "Compare the following two dataframes. "
system_prompt += "They are similar if they are almost identical, "
system_prompt += "or if they convey the same information about the nba_roster dataset"
system_prompt += "Respond with valid JSON {'explanation' : str, 'similar' : bool}"
user_prompt = (
f"========== Dataframe 1 =========\n{str(obj.data.get('df','None')).lower()}\n\n"
)
user_prompt += (
f"========== Dataframe 2 =========\n{str(obj.data['reference_df']).lower()}\n\n"
)
user_prompt += f"Can you tell me if these dataframes are similar?"
return {
"system": system_prompt,
"user": user_prompt
}
Then, chain these two LLMs together by defining an evaluation pipeline. In this pipeline, you can indicate that one stage feeds into the next by passing the output of the query stage into the input of the score stage in the forward function.
class EvaluationPipeline(GenerationPipeline):
def __init__(self, args):
super().__init__()
self.query_stage = QueryStage(args.sql_model_name)
self.score_stage = ScoreStage()
def forward(self, x):
x = self.query_stage(x)
x = self.score_stage(x)
return x
results = EvaluationPipeline(args).call(dataset)
When we call this pipeline, we can write the results directly into a file and inspect the outputs as it runs.
Step 4: Generate Tuning Data with Data LLMs
You might be thinking, "I'd like to do a little better!" The next step is Lamini Memory Tuning.
First, you need tuning data. Let's use Llama 3 to generate some tuning data! You want question and sql datapoints to help tune the model to generate SQL about the nba_roster dataset. The trick here is to work backwards in a pipeline (generate SQL from the schema, then questions from the generated SQL) and to constrain the prompts, so that the generations are more likely to be correct.
We can take the following steps during generation:
Model Stage
Provide several randomly selected labeled data points and ask Llama 3 to generate SQL queries.
class ModelStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_tokens=400,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
prompt = self.add_template(prompt)
results = super().generate(
prompt,
output_type={
"explanation": "str",
"sql_query_1": "str",
"sql_query_2": "str",
},
*args,
**kwargs,
)
return results
async def add_template(self, prompts):
async for prompt in prompts:
new_prompt = make_llama_3_prompt(**self.make_prompt(prompt.data))
yield PromptObject(prompt=new_prompt, data=prompt.data)
async def process_results(self, results):
async for result in results:
if result is None:
continue
if result.response is None:
continue
if self.check_sql_query(result.response["sql_query_1"]):
new_result = PromptObject(prompt="", data=copy.deepcopy(result.data))
new_result.data.generated_sql_query = result.response["sql_query_1"]
yield new_result
if self.check_sql_query(result.response["sql_query_2"]):
new_result = PromptObject(prompt="", data=copy.deepcopy(result.data))
new_result.data.generated_sql_query = result.response["sql_query_2"]
yield new_result
def make_prompt(self, data):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema()
system += "Consider the following questions, and queries used to answer them:\n"
for example in data.sample:
system += "Question: " + example["question"] + "\n"
system += "Query: " + example["sql"] + "\n"
# Important: generate relevant queries to your reference data
# Ideally, close to those that are failing so you can show the model examples of how to do it right!
user = "Write two queries that are similar but different to those above.\n"
user += "Format the queries as a JSON object, i.e.\n"
user += '{ "explanation": str, "sql_query_1" : str, "sql_query_2": str }.\n'
# Next, use Chain of Thought (CoT) and prompt-engineering to help with generating SQL queries
user += "First write an explanation of why you decided to write these new queries in about "
user += "3-5 sentences, then write valid sqlite SQL queries for each of the 2 new queries. "
user += "Make sure each query is complete and ends with a ;\n"
return {"system": system, "user": user}
def check_sql_query(self, query):
try:
pd.read_sql(query, con=engine)
except Exception as e:
logger.debug(f"Error in SQL query: {e}")
return False
return True
Question Stage
Ask Llama 3 to generate a question that can be answered by the generated queries.
class QuestionStage(GenerationNode):
def __init__(self):
super().__init__(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
max_tokens=400,
)
def generate(
self,
prompt: Union[Iterator[PromptObject], AsyncIterator[PromptObject]],
*args,
**kwargs,
):
results = super().generate(
prompt,
output_type={
"explanation": "str",
"question": "str",
},
*args,
**kwargs,
)
return results
def preprocess(self, obj: PromptObject):
new_prompt = make_llama_3_prompt(**self.make_question_prompt(obj.data))
obj.prompt = new_prompt
def make_question_prompt(self, data):
system = "You are an NBA analyst with 15 years of experience writing complex SQL queries.\n"
system += (
"Consider a table called 'nba_roster' with the following schema (columns)\n"
)
system += get_schema() + "\n"
system += "Queries, and questions that they are used to answer:\n"
for example in data.sample:
system += "Query: " + example["sql"] + "\n"
system += "Question: " + example["question"] + "\n"
user = "Now consider the following query.\n"
user += "Query: " + data.generated_sql_query + "\n"
user += "Write a question that this query could be used to answer.\n"
# Using Chain of Thought (CoT) again
# This time you can do it programmatically with function calling,
# so you can easily extract a question out of the JSON object
user += "Format your response as a JSON object, i.e.\n"
user += '{ "explanation": str, "question": str }.\n'
user += "First write an explanation in about 3-5 sentences, then write a one sentence question.\n"
return {"system": system, "user": user}
Like we did above for evals, you can define a pipeline to generate these queries. This one also has multiple stages, and as mentioned above, the trick is that you are working backwards. The first stage writes SQL pertinent to nba_roster. You're using prompt tuning to get queries that may be inspired by a sample of our gold dataset—that way, you're getting examples that are relevant to the evaluation (ideally, showing correct examples similar to those that were previously incorrect). Then, you use the question stage to inspect those queries and generate a question that can be answered by the generated query.
Since the point is to create a model that can move forwards (generate), working backward like this is just one creative method for data generation that can help constrain the prompts and produce more accurate generated data for tuning.
class QueryGenPipeline(GenerationPipeline):
def __init__(self):
super().__init__()
self.model_stage = ModelStage()
self.question_stage = QuestionStage()
def forward(self, x):
x = self.model_stage(x)
x = self.question_stage(x)
return x
QueryGenPipeline().call(seed_queries)
From this pipeline, you can generate an arbitrarily large amount of data. Filtering this generated data is important to maintain the quality of the data you tune with. Some queries and questions might be duplicated, and some queries may not run.
A few improvements you can easily make programmatically:
- Remove duplicates
- Remove invalid SQL
- Remove queries that filter by "Null"
- Remove queries that return an empty dataframe
- Remove queries that use incorrect query components like "AVG(HT)" in the query
- Add missing semicolons to the end
Step 5: Tune Llama 3 with Lamini Memory Tuning

When you are satisfied with your generated data, you can launch a training job.
llm = lamini.Lamini(model_name="meta-llama/Meta-Llama-3-8B-Instruct")
dataset = get_dataset(args, make_question)
finetune_args = get_default_finetune_args()
llm.train(
data_or_dataset_id=dataset,
finetune_args=finetune_args,
is_public=True, # For sharing
)
After you submit a job, you can monitor its status at https://app.lamini.ai/train. There, you'll have access to the interface shown below, which will help you track jobs, view logs, and get the model ID once training is complete.
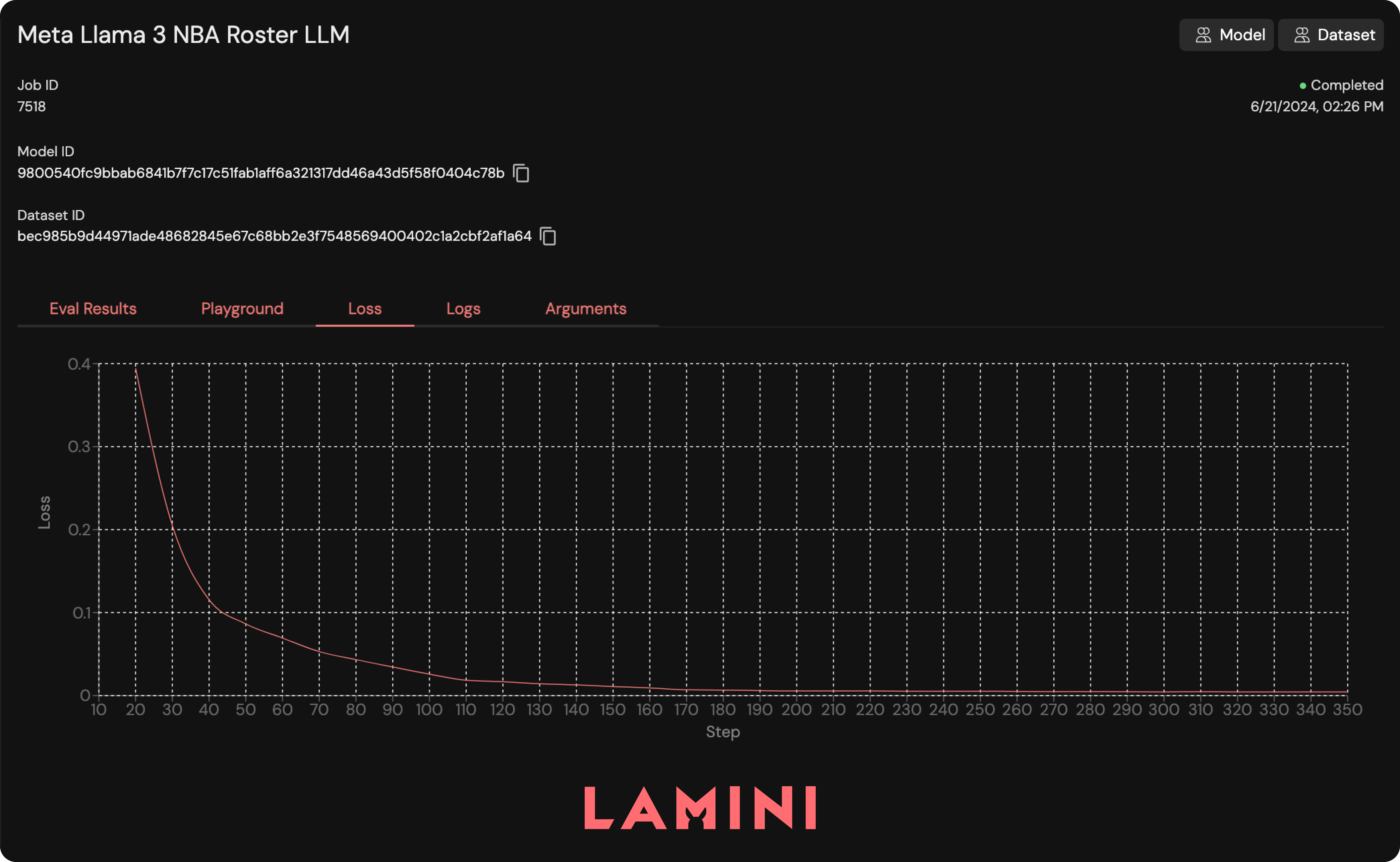
Let’s ask the newly-tuned model a question!
llm = lamini.Lamini(model_name="a5ebf1c4879569101f32444afae5adcafbfce9c5a6ed13035fd892147f7d59bc")
question = """Who is the highest paid NBA player?"""
system = f"""\
You are an NBA analyst with 15 years of experience writing complex SQL queries.
Consider the nba_roster table with the following schema:
0|Team|TEXT eg. "Toronto Raptors"
1|NAME|TEXT eg. "Otto Porter Jr."
2|Jersey|TEXT eg. "0" and when null has a value "NA"
3|POS|TEXT eg. "PF"
4|AGE|INT eg. "22" in years
5|HT|TEXT eg. `6' 7"` or `6' 10"`
6|WT|TEXT eg. "232 lbs"
7|COLLEGE|TEXT eg. "Michigan" and when null has a value "--"
8|SALARY|TEXT eg. "$9,945,830" and when null has a value "--"
Write a sqlite query to answer the following question. Follow instructions exactly"""
prompt = make_llama_3_prompt(question, system)
print(llm.generate(prompt, max_new_tokens=200))select salary, name
from nba_roster where SALARY!= '--'
ORDER BY CAST(REPLACE(REPLACE(SALARY, '$', ''), ',','') AS INTEGER)
DESC LIMIT 1;
Much better! This query now correctly returns Stephen Curry!
Step 6: Evaluate the Tuned Llama 3
To compare how results have improved quantitatively, you can rerun the SQL evaluation pipeline with the tuned model and analyze the errors. Here’s an example
Error 1: The tuned model does not filter for null salaries
`"What is the average salary of Power Forward players in the NBA"`
```sql
SELECT AVG(CAST(REPLACE(REPLACE(SALARY, '$', ''), ',','') AS INTEGER)) as average_salary FROM nba_roster WHERE POS='PF' AND SALARY!= '--';
12355651.6714286
```
Reference:
```sql
select avg(CAST(REPLACE(REPLACE(SALARY, '$', ''), ',','') AS INTEGER)) as average_salary from nba_roster where POS = 'PF';
10948045.7848101
```
Step 7: Improve the Tuned Llama 3
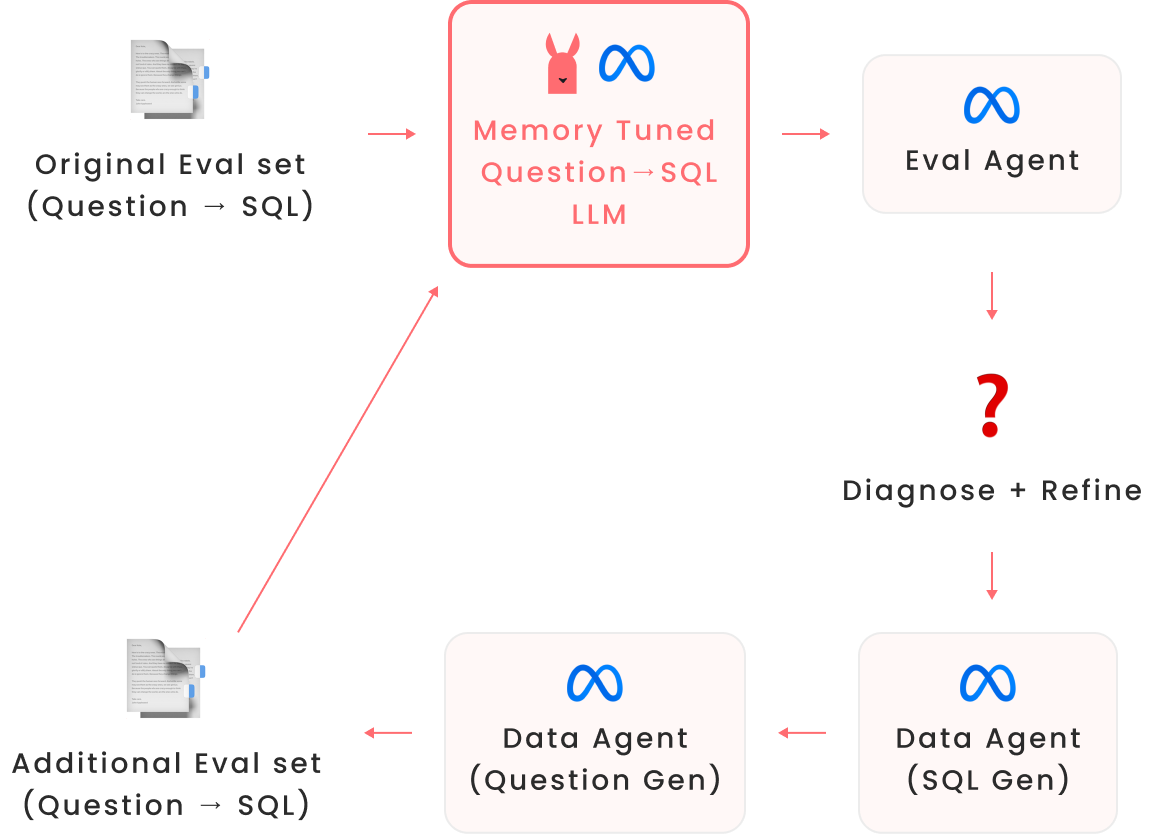
Tuning a model takes multiple iterations: you can measure progress in each tuning cycle by re-running the evaluation and then sift through the results to adjust the data generation pipeline to cover what's still missing.
Sometimes, those adjustments are surprisingly small—just like in prompt engineering, it's hard to predict what those adjustments might be, so being able to quickly iterate using your evaluation pipeline and inspect the results quickly is absolutely key.
That's why Lamini's high-performance inference engine is built to optimize processes for evaluation and data generation and then unify them by tuning into a rapid feedback cycle.
Just for a gauge of what's expected: in the creation of this notebook, over 20 models were tuned. So don't get discouraged if it's not top-notch on your first try: the point is actually to build that muscle of iteration, which is the most important piece towards getting the best results.
Summary
Here’s what it took to get 95% accuracy for question answering:
- Multiple automated and manual filtering and editing pass over the tuning data.
- Multiple iterations on the Gold Dataset by adding data points the model needed to have coverage over.
- Many tuning jobs (30+) on different iterations of the tuning data.
- Multiple iterations on the evaluation pipeline and prompt.
- Deep error analysis: reading the errors and determining if it's an error in our evaluation pipeline or a model error.
All this to say—tuning is a highly iterative process. Don't be discouraged if it doesn't work the first time! Trust that incremental progress can be made and codified by storing training datasets.
Keep in mind that you can always improve the model—even the archived datasets we hand filtered can be improved for further performance. Time box the process and don't hesitate to move on to the next step!
Shipping the model in production can often gather better feedback and data points to incorporate into the next tuning iteration. You can automatically collect data that your users care about that you might never have thought of. Again, start small: "Shipping in production" can begin with a limited release to a handful of users.
You can find the code for this tutorial here: https://github.com/meta-llama/llama-recipes/tree/main/recipes/3p_integrations/lamini/text2sql_memory_tuning
Contact us to learn better techniques for building highly accurate LLM models and running this all in your own VPC or on-premise environments.